If you’ve ever tried to track changes to your Salesforce records in detail, you’ve probably run into some frustrating limitations. Out of the box, Salesforce lets you track field history – but only for up to 20 fields per object. That limit can be increased to 60 if you purchase Salesforce Shield, but even then, it’s still… well, limited.
And it gets trickier. If you’re using Long Text or Rich Text fields, Salesforce won’t show you what actually changed – just that something did. For many users, this basic level of field tracking is enough. But for organisations that need deeper, more reliable auditing – like regulated industries or those with strict compliance requirements – the standard options just don’t cut it.
There are a number of ways to solve this problem on the platform, such as creating Custom Objects to store field changes or using a Big Object. These solutions will consume either Data Storage or Big Object storage limits.
Data Storage on Salesforce is not cheap, but it is simple to calculate. Every record is 2kb, and the base storage for most organisations starts at 10GB, rising based on licences purchased. At this base level, this would give you (in a perfect database) 5 million records.
Salesforce record size overview
Using valuable and expensive Data Storage for audit information, which is Write Once Read Many (WORM) data, is an inefficient use of your storage allowance.
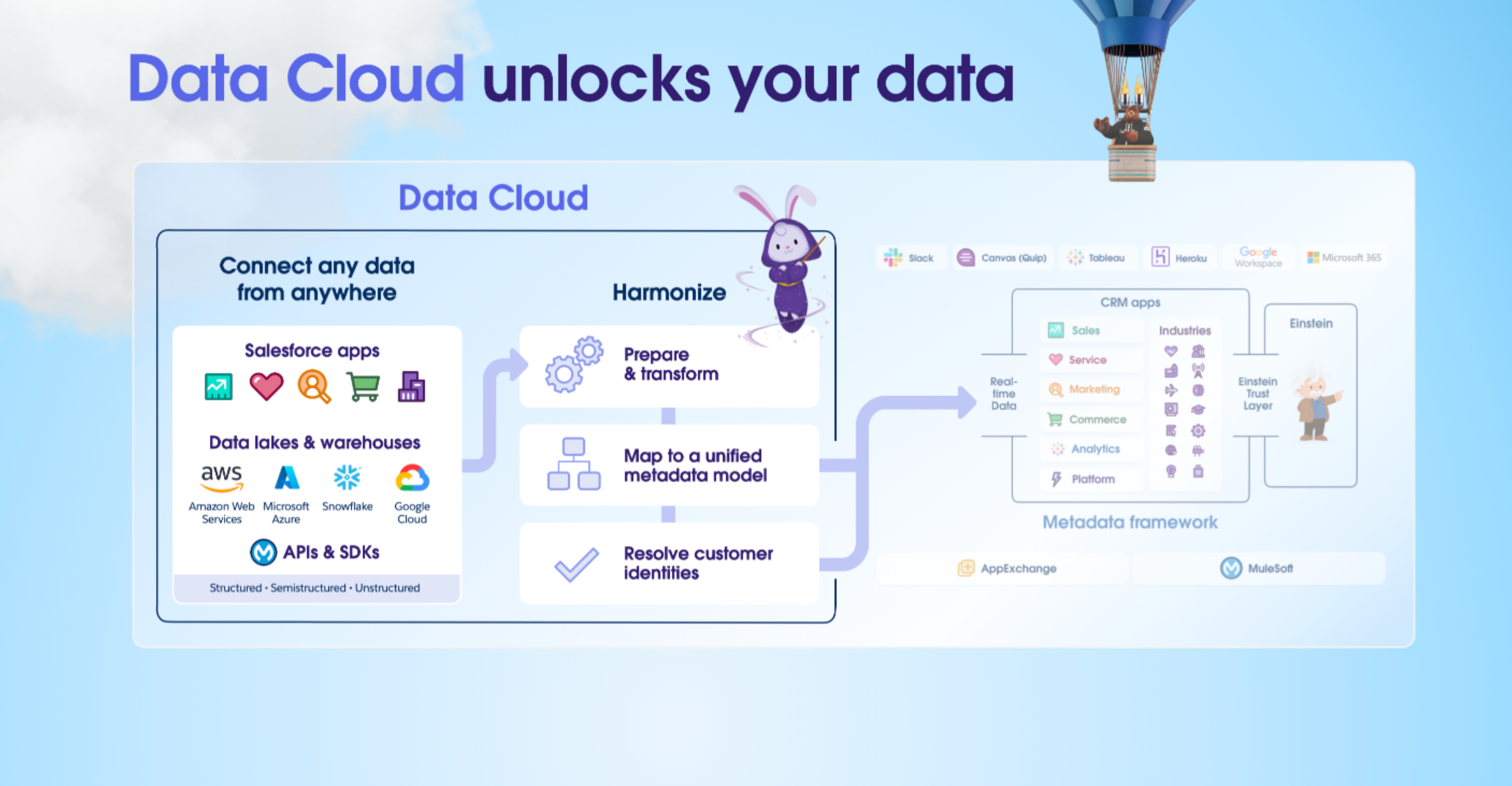
Data Cloud to the rescue
Salesforce is much more generous with its Data Cloud storage provision, with as much as 1TB (1000GB) of data available to use for most organisations.
Read more about Salesforce Foundations here
Storing this audit data in a Data Cloud Data Lake Object (DLO) offers greater flexibility. No longer will you be limited to just Custom Objects or Big Objects; Data Lake Objects can hold much more data, and are much cheaper to use.
DLOs and their mapped Data Model Objects (DMOs) can be easily queried via Apex and SOQL, so surfacing that data in the UI is entirely possible, albeit with some customisations.
What about consumption costs?
Many organisations are concerned about how many credits they’ll use when using Data Cloud, and Salesforce’s credit consumption model can be complex. Getting data into Data Cloud isn’t ‘free’ but isn’t as expensive as you’d believe.
Recently, Salesforce slashed the credit multiplier on internal data ingestion from 2,000 to 500, and this is a step in the right direction. In practical terms, this translates to 500 credits for importing 1,000,000 rows of data. If you were using 10GB of data storage (5M records), this would equate to an initial import cost of 2,500 credits. Updates to these records also incur costs, as each re-import results in an additional credit charge (0.0005 credits per record). Records aren’t ingested in real-time, instead, they are batched and processed around every 15 minutes (it varies).
Streaming data (event-based) is more expensive at 5,000 credits per 1,000,000 rows of data (or 10x on the internal data), which would be 0.005 credits per record.
“Why You Should Care About Data Cloud”
Getting the data back out again, using a Data Query will also incur a credit cost, but this is much lower than the ingestion costs, currently with a multiplier of 2 per 1,000,000 rows of data returned. In this instance, if we were using this for Field History tracking, I would make the screen component only return data when requested by the user, reducing the costs where possible.
Is this a good idea?
For some organisations, sure, this is a good idea, especially when you consider the cost difference between using Data Cloud vs Data Storage for this type of data. Using 100,000 records as an example, and assuming Data Cloud and Salesforce Data Storage use the same storage amount per record, approximate costs to store this data would be $19.07 on Salesforce and $0.03 on Data Cloud. This is based on the list price of $1000 per month for 10GB of Salesforce Data Storage and $150 per month for 1TB of Data Cloud storage, 680x cheaper to use Data Cloud.
However, there are potential resource implications such as system limits, and bulk updating of records. This approach is not without its challenges and requires thorough testing before production deployment.