
Rivers, and paddling them in a canoe, can teach you important lessons about going with the flow. You’re never going to successfully paddle upstream against the Yukon (trust me – I’ve been there). Poor communication with a tandem canoe partner can make you both end up swimming. If you get pinned sideways, you must lean in to the obstacle.
The most important lesson, though, is the first one: Go with the flow. Let the river guide you. Work together to get the boat where it needs to be. All that power, blended with a bit of control, can have beautiful results.
As Salesforce have built up their Flow tool, developers have a decision to make. Do we paddle furiously against the river? Or do we put our paddle in, and see what we can do with it?
The following is a series of experiments and observations on Flow from a developer looking to understand what this tool can offer us. It has helped me to figure out:
- What Flow is good for
- How to make an informed choice between Flow and Apex
- The performance tradeoffs between Flow and Apex
- How to extend Flow with Apex in important ways
- How to test Flow in Flow itself
- What all this means for Apex
Method
I have spent a lot of time working with Apex over the years, but I only had a passing acquaintance with Flow. In order to dig into Flow in a meaningful way, I took a three-pronged approach:
- Read the Salesforce Architects Decision Guide on triggered record updates. This excellent guide describes how the technical (rather than marketing) teams position Flow.
- A couple of Trailhead trails to learn the builder tool.
- Attempt to recreate a programming exercise that I’m familiar with from Apex in Flow.
This allowed me to understand Flow from above (1), from below (2), and exploding out of its middle (3).
Flow from above
It’s worth reading the whole of the architects’ decision guide. But, for the impatient, here are a few important points about Flow:
- Process Builder and Workflow are no longer recommended. Flow should be used instead. There are some functionality gaps in Flow (with a timetable for addressing them). But Flow should be the first non-Apex choice for automation.
- Same record updates (e.g. a Flow triggered by a Contact record writes back to the same Contact) are hugely more efficient in before-save Flow than Process Builder or Workflow.
- There is no built-in way to access the old records from a triggered Flow (there are workarounds).
- Flows are not evaluated recursively, even if some other automation causes the same record to be updated twice in the same transaction. See my GitHub project on this.
- Apex is not evil – if you have complex requirements and/or a strong Apex team, use Apex.
Flow is programming
Low code, no-code, “pro” code… What does it all mean? Honestly, it probably means something different to each person.
The important thing is that Flow is programming. And so, it comes with all the power and danger that this brings. You’re dragging boxes and drawing lines. But you’re also having to think about variables and loops. You should be just as concerned as a diligent Apex developer about factors such as:
- Managing changes to specification/requirements
- Error handling and reliability
- Effective testing
- Efficiency
- Managing complexity by introducing abstractions
- The Flow’s place in the larger system
Note that I listed these as the concerns of “a diligent Apex developer”. If you ignore these points in Apex, you’ll end up with a mess. However, there are books and articles to guide you on how to manage Apex effectively. Flow is too new for that, and it’s not obvious how to address the points above with the tools we currently have.
Throwing people with no previous experience of programming into Flow, and suggesting that they can solve every problem with it is just madness. There is more to coding than just learning where the curly brackets go. With Flow right now, there’s a great opportunity to figure out the best ways of using it. Ways that can satisfactorily answer the points above.
A programming exercise
Here’s a simple scenario that I’ve asked people to do in Apex over the years.
The only objects involved are standard Accounts and Contacts. Account has a new field on it, called Newest_Contact__c. This is a lookup field to Contact. And the challenge is to write code to automatically populate that field with the most recently added Contact on any particular Account. If there is more than one Contact inserted for the same Account in the same transaction, we don’t care which one becomes the Newest_Contact__c.
After a little thinking, you may realise that there are three main scenarios:
- Insert – when a new Contact is inserted with AccountId filled in, it becomes the Newest_Contact__c.
- Update – when a Contact is transferred, we need to re-evaluate the new and old Accounts, as both might have changed their Newest_Contact__c.
- Delete – when a Contact is deleted, we need to re-evaluate the old Account.
If you’re being careful, you may consider what happens when AccountId is null (or becomes null), and also the undelete scenario.
Note that in the following, I’m using the contact’s first name to determine which automation should handle any particular contact.
Newest Contact: Insert
In Apex, this is simple. On insert, loop through the new Contacts and check whether they have an Account Id. If they do, create an in-memory Account with the Newest_Contact__c field filled in, for updating later. Collect all the accounts into a Map to make sure they are unique on Id, then update them.
Gratifyingly, this is just as simple in Flow:
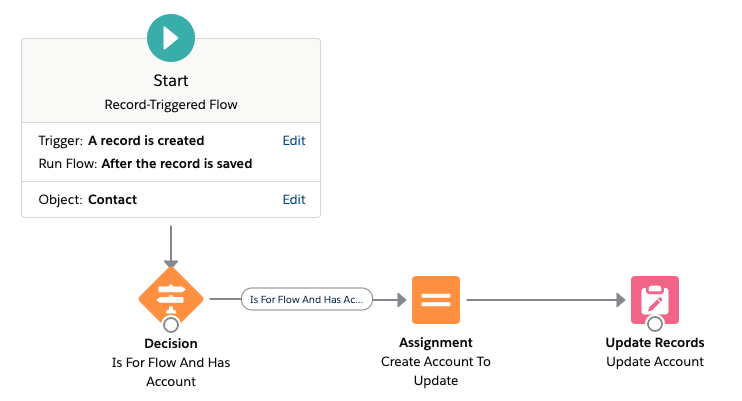
We can see the same three stages:
- Decide if we need to update any Account.
- Create an Account in-memory to update.
- Update the database.
In some ways, the Flow is clearer because it’s working at a higher level of abstraction.
We can also see that the Flow is written in terms of a single record. And Flow handles bulkification. That update at the end is written in terms of a single record. But Flow is gathering together all the records in the trigger and only doing one DML statement. It is also deduplicating ids so that two Contacts inserted on the same Account do not clash by trying to update the same Account twice.
Newest Contact: Update
Conceptually, we need to trigger on change of Contact.AccountId. When that happens, we need to collect both the old and new Account ids. Then re-evaluate the Newest_Contact__c for all such accounts.
In Apex, finding the Account ids is straightforward. Then, updating the Accounts can be done fairly easily by querying them with the newest contact as a subquery:
(Note that we remove null from the accountIdsToUpdate because querying against a collection containing null can cause a table scan).
In Flow, we run into a problem. There is no access to the old records from the trigger context. So, we cannot fully implement a working solution without some help.
Flapex to the rescue!
A colleague of mine coined “Flapex” as the term for when Apex actions come to the rescue of Flow. Not to do a specific one-off task, but to raise the game of what’s possible in Flow. In my journey into Flow, I’ve discovered a few places where Flapex can help. And I’m not the only one. There are components you can download at Unofficial SF and on Github.
In the case of wanting access to the old trigger context, a key thing to know is that static variables in Apex persist for the life of a transaction. A whole transaction. So, I can record the old records in an Apex before trigger. Then read them in an Apex after trigger. They even persist to the part of the transaction where Apex invocable methods are called. Once you know that, the Apex code is simple:
Once this code is setup to run on Contact before update via our trigger framework, we can call it at the beginning of our Flow to obtain the old Contact record.
Even so, the Flow is quite long:
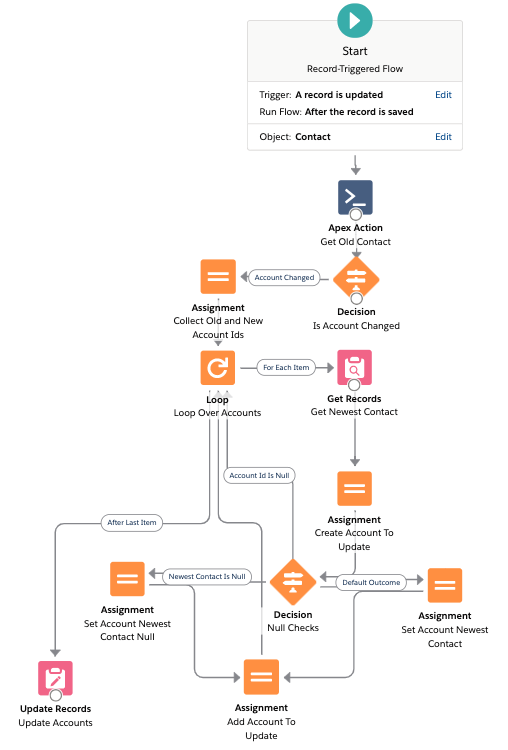
Here’s what it’s doing:
- We start by checking whether or not the AccountId has changed
- If there’s no change, then just exit
- If there is a change, put the old and new Account Ids into a collection variable
- Then loop over those Account Ids
- For each Account Id, query the newest contact
- Then, create an in-memory Account with the Newest_Contact__c set to the newest contact id or null
- Add each of those in-memory Accounts to a collection
- Finally update that collection in the database
Note that we have to check whether the AccountId in the loop is null. Or else the final update will fail (you can’t update with no id). This is only discovered with good testing (see below). And it could be done more efficiently earlier in the loop. I put all the null checks into one decision node to reduce the total number of nodes, and hopefully improve clarity in the example. It does, however, show some of the design decisions involved in coding a Flow.
SOQL in a loop? Really?!
An Apex developer is going to look at the “Get Records” inside the loop and furrow their brow. SOQL in a loop? Problem. The good news is that this loop is only ever over two records: the old and new account ids. Even when you run the Flow on 200 records, it still runs just 2 queries because Flow is bulkifying the rest for you.
Nonetheless, in Apex, we would do one big query outside the loop. Then use a map to extract the results we wanted on each iteration.
There is no map built into Flow, but Flapex comes to the rescue again.
We can have an Apex Action which creates a map of AccountId to Contacts, this can persist in a static variable in the Apex, and return an integer handle to the particular map. Later on in the Flow (in the loop) we can retrieve records from the map by using the integer handle and the key we want to retrieve.
The Flow looks like this:
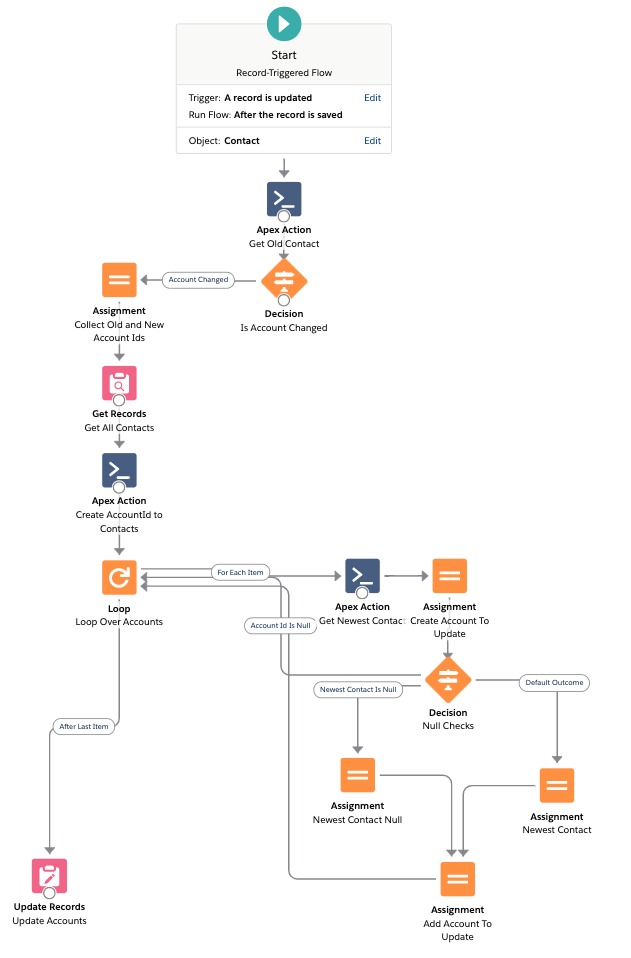
This Flow is similar to the first one, but we query the Contacts outside the loop, and put them into a map of AccountId to Contact. The loop then retrieves the newest contact directly from the map, with no need for further queries.
The Apex is fairly simple again, although it is leveraging a component from our library called SObjectIndex. Which is like a generalised version of map that can store on multiple keys, and also store a list of records for each key.
The Apex Actions for this consist of three classes.
FlowSObjectIndex holds a static list of SObjectIndexes:
FlowSObjectIndexCreate takes a list of requests. A list because a Flow can run many instances in parallel to bulkify them. Each Flow instance is passing in a field to index on, and a list of records to put in. We’re going to assume that the field is the same in every request, but that the records may vary. So, we create a single instance of SObjectIndex, indexing on the given field. Then we add all the records from all the requests. Finally we return a handle to the SObjectIndex – its position in the array. This way, the Flow can use multiple FlowSObjectIndexCreate nodes to store maps with different indexes/data.
FlowSObjectIndexGet takes a handle (the result of FlowSObjectIndexCreate) and a key. It gets the appropriate SObjectIndex, and returns a result from it. Note: a proper implementation would be able to return the whole list from the key, but this is just proof-of-concept.
This general technique of creating complex data structures in Apex, and passing handles back to Flow really opens up many possibilities for making Flow more expressive.
Won’t someone think of the limits?!
Performance is always going to be a consideration. But unless the performance is grossly awful, or you’re working in a domain where it’s absolutely critical, then it’s not the top priority.
In order of priority, the limits we care about in Salesforce are:
- Number of database commits (i.e. DML) – first priority because these can cause other automation to run and suck up more resources.
- Number of database queries (i.e. SOQL) – second because the limit is fairly low.
- CPU time – important because it’s global across namespaces.
As well as absolute numbers, we also care about how these numbers grow when the number of records in a transaction increases (the Big O classification). And we balance these against non-performance factors: speed of development, maintainability within the company, flexibility to change.
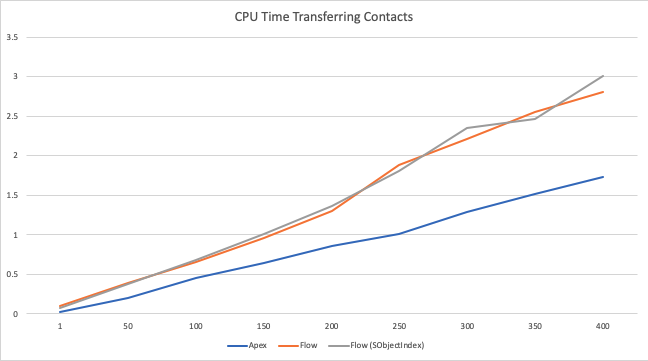
I ran some experiments with the update case of Newest Contact, transferring various numbers of contacts between Accounts.
For DML statements, Flow starts off equal to Apex, but then (in this example) adds 2 extra DMLs for each extra chunk:
| DML | n ≤ 200 | 200 < n ≤ 400 | 400 < n ≤ 600 |
|---|---|---|---|
| Apex | 1 | 2 | 3 |
| Flow | 1 | 3 | 5 |
| Flow (SObjectIndex) | 1 | 3 | 5 |
This is a bit mysterious, but perhaps one of those things that will be improved over time.
In SOQL, the results are exactly as you would expect. Apex takes 1 per chunk, Flow without SObjectIndex takes 2 per chunk, and Flow with SObjectIndex takes 1 per chunk:
| SOQL | n ≤ 200 | 200 < n ≤ 400 | 400 < n ≤ 600 |
|---|---|---|---|
| Apex | 1 | 2 | 3 |
| Flow | 2 | 4 | 6 |
| Flow (SObjectIndex) | 1 | 2 | 3 |
CPU benchmarking is hard, so I won’t claim my tests to be exhaustive. However, the results hang together quite consistently. As you can see from the graph, Flow is slower than Apex but not by a huge margin – and they both look to grow linearly in the number of records. So, it is quite probably good enough for most situations. Using SObjectIndex inside the Flow has not cost anything significant from the CPU time, but it has saved a SOQL per chunk, so it’s a useful improvement.
What about testing?
Tests should be fast, automated, repeatable, and isolated from production data. Apex is great at this. We write a test class, and that class runs against an empty database. The test creates all the records it needs, exercises them, and verifies the results. At the end of the test, the real database is unaffected.
Really, something similar is required for Flow, and the tests themselves should be written in Flow.
So, I thought about this for a bit, and realised this: Apex already has all the good stuff for tests, and we can invoke Flow from Apex, so we could write our tests in Flow and automatically generate simple Apex Test classes that simply run the given Flow, e.g.:
This would allow our Flow tests to run alongside Apex tests, but be created entirely inside Flow. All we need is some convention such as adding @IsTest to the Description of the Flow, then an Apex class can use the Tooling API to generate test classes for every test Flow. This is left as an exercise for the reader (and hopefully an exercise for Salesforce themselves, if they’re listening).
But how do you write a test in Flow?
Assertions are simple – we can just create some invocable Apex actions for Assert Equals, Assert True, Assert Not Equals, and so on, e.g.:
Creating test data is not so simple. Any moderately advanced Apex codebase will have some sort of factory for creating test data. This centralises the knowledge about what constitutes a valid record. So, if a new required field is added, modifying the factory fixes all the tests. It also helps to keep each test concise by shortening the setup code. Many test factories automatically create the records that the requested record depends on, e.g. if you create a test Opportunity Line Item, a good factory will automatically create an Opportunity without being asked. Any solution for Flow tests has to offer some sort of test data factory, or it’s never going to get beyond being a toy.
So, Flow needs a Flapex action to generate test data which hooks into an Apex test data factory. Since Apex doesn’t allow reflection, that data factory cannot have a collection of methods like getContact(), getAccount() and so on because we can’t dynamically call them based on parameters coming from Flow. Fortunately, the test factory from our Nebula Core library uses custom metadata and dependency injection to create records. This fits perfectly with the requirements for Flow. The required invocable actions look like this:
Variant here is a concept from our test factory. You can define templates for multiple variants of the same record type. So, we might have Account variants for Customer, Supplier, and more. The custom metadata then specifies that each has a different record type, and maybe different fields filled in. From Flow, you can get all that detail just by requesting the right variant.
Note that we treat the input of specifications as if there is only one item in the list. The test Flow will only be run from Apex, so it won’t be bulkified, making this a legitimate choice.
With these pieces, we can write some test Flows. First, we test the case of inserting a Contact against an Account. The Flow just creates an instance of each by calling the Apex Actions. The record triggered-flow will then have run as the Contact was inserted. So we can query back the Account to check the results. A final Apex Action asserts that Newest_Contact__c is correct.
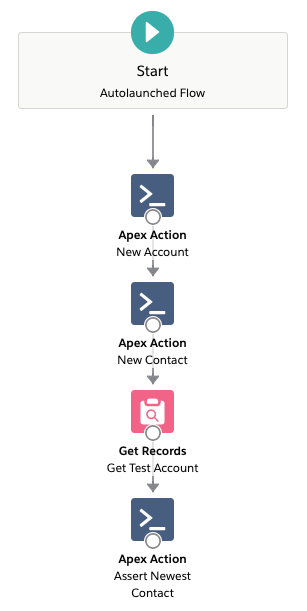
OK, but how about a real test?
That test was simple. Can we really write proper tests in Flow? This time, the test is to add 2 Contacts to a single Account and make sure that one of them is the Newest_Contact__c. This makes the assertion tricky. We want to assert that either of them could be the right one. And in Flow, the only way I could come up with was to do a loop over the 2 Contacts, recording in a Boolean flag whether or not one of them was the Newest_Contact__c. (Note – it looks a bit different to the others because it’s using Winter 21’s auto-layout feature to do a nice job):
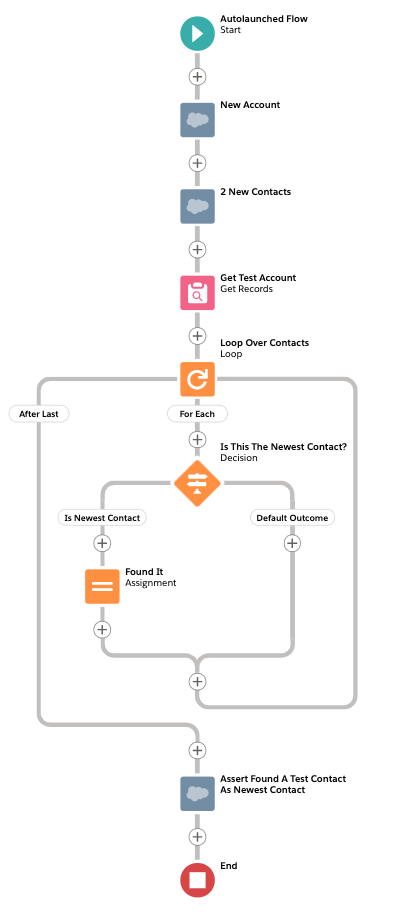
So, we can do a lot with testing in Flow. And, perhaps if you cannot write a good test for it in Flow, this might be a hint that it’s time to move the whole thing to Apex anyway.
Some general considerations on Flow
As with Apex, names matter. Each node should do what its name suggests, and nothing more. There should be no surprises when you look inside a node/method. Salesforce include suggestions for Flow nodes in their recent document about naming conventions. By following those conventions, your Flow will be both readable and consistent with others who do the same.
In code, we’d often say that a class should be no larger than a screen-full. Once it’s bigger than that, it’s too much to easily reason about. A similar consideration should be given to Flow. If it’s much more than a screen-full, it should be broken down or perhaps done in Apex.
The bulkification built in to Flow is really quite elegant, and eliminates a lot of the need for explicit map structures as we would see in Apex. In Apex we often query into a Map<Id, SObject> and then retrieve items from that map inside a loop over all the trigger records. Flow’s bulkification means that we write our flow code in terms of a single record. When we use “Get Records” in Flow, it does something map-like in the background to give us the records we need. It is really a quirk of the Newest Contact problem, that forced me to use a SObjectIndex to marshall my query data. The gap for exposing a simple map from Apex to Flow is probably quite small. But the concept of having more complicated data structures written in Apex and accessible in Flow is quite powerful.
Some of the larger Flows I’ve seen are large because they are enumerating all the possible options, rather than using any sort of abstraction. This is like someone writing Apex using only if/else and switch. It’s easy, but it’s not simple. It’s no good for humans to read, and it’s hard to update. If you find yourself doing that, think again. There must be a better way. The use of SObjectIndex above will buy you out of a lot of such situations.
Write good Apex!
If you’re a developer worried that Flow might swallow up your job, then you should take it as a challenge. First to learn Flow, and second to write better Apex.
One reason that customers may prefer Flow is that they can modify some parameters of the Flow after delivery. If you write your Apex to be configurable via custom metadata or similar, then you still achieve that goal. I would argue that this is better than using Flow for reconfiguration. Custom metadata explicitly describes what can change, and the design can expect such changes. Allowing someone to modify any part of a Flow (directly in production?!) is more dangerous. The modifications could be buggy, or break design assumptions that have wider implications.
Flow is bulkified by default. It’s slower than well-written Apex, but raises the bar on poor Apex. You need to make sure that you’re on the right side of that equation by making sure that your Apex is good.
Flow covers the territory that used to be covered by simple Apex triggers, so maybe we won’t write so many simple triggers. This is a good thing! There is still a need to handle asynchronous code, large volumes, callouts, fault tolerance, and so on. Get good at those interesting areas, and let Flow take up some slack on the boring stuff.
Conclusions
I have a found Flow to be a pleasantly useful tool. I would still pick Apex first most of the time, but understanding it so that I can work with non-Apex developers is very useful.
In recent weeks, I’ve twice helped our consultants to do something in Flow instead of any other tool and found that the solution was a before-save Flow with just one node. That says a lot about how much low hanging fruit Flow can scoop up.
Flapex is a really powerful idea. I had seen (or perhaps misunderstood) Flow/Apex being sold as the idea that an admin would build a Flow and get an Apex developer to create point-solutions for various functions that they might need along the way. The developer might get clever and try to make those components more generic, but they’re still in the business of making point-solutions on-demand. Instead, we can make Apex components which increase the expressiveness of Flow, allowing admins to build more in Flow. This adds the most value with the least code.
The fundamental difficulties of writing code don’t go away with Flow. In fact, they might get worse as the ease of entry leads people into danger more quickly. If everyone can develop a sense of best practice and a nose for bad smells in Flow, it’s going to make automation on the platform a better place.
The code in the repository for this is open-source and available to use. I’m not sure I would go using it just yet. It’s there to show my working; to give you a head start if you run with this. It may form the basis of a more fully thought-out library of Flow components that I put together in the future. I do welcome comments on it though.